
You’ve probably heard it all over: GEO, AEO, LLMO… so many acronyms tied to website rankings in the AI space, each one claiming to be the most important thing you should do for your site right now.
And while it’s true that AI is here to stay and will gradually reshape the optimization landscape, it’s important to first understand the fundamentals of how data is retrieved, before making bold moves out of fear of falling behind.
In this article, I’ll explain in a simple, plain manner, how large language models (LLMs) like GPT actually retrieve and generate information.
Grab your coffee and get comfortable, (there’s a bit of reading ahead) and let’s dive in.
The evolution of AI: From Research Labs to Real Life
LLMs might seem like a wonder to us, and for good reason. But they aren’t as new as they appear. The real turning point came when they became available to the public, grabbing attention in the blink of an eye.
From “Correct my grammar” and “Rephrase this email” to… You guessed it: Being used like a search engine.

We began asking AI not only for things we wanted to know, but also for things we wanted to find… on websites.
But how does AI actually find that information?
The mechanism behind it isn’t as complex as it may seem. Keep reading. I’ll Walk you through it in plain language so you can get a sense of what happens behind the scenes, or better said, behind the algorithm.
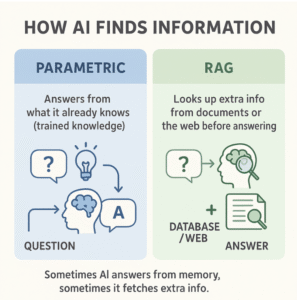
Parametric Knowledge: The Main Default Setting
Imagine an AI that studied a massive portion of the internet up until a certain cutoff date, absorbing content from blogs, Wikipedia, books, public forums, and other relevant sources. That’s how AI “feeds” its parametric knowledge.
When AI models rely on their parametric knowledge (what they learned during training), they’re working entirely from “memory.”
When you ask it something, it generates a response based on patterns it recognized during training — no real-time lookup involved.
Instead of “finding” an answer, it predicts the next likely words based on what someone would expect to read in response to your question, using everything it learned during training.
Think of this like taking an exam where you rely solely on what you’ve studied — answering from memory without access to reference material.
Many AI tools still use parametric knowledge as a foundation, but it’s increasingly blended with real-time retrieval, depending on the tool and context.
If your website wasn’t part of the training datasets or was published after the cutoff date, the AI might not know it exists — unless the system can look it up using retrieval.
And that’s where RAG comes in.
RAG: When AI Goes to Look Something Up
RAG (Retrieval-Augmented Generation) is more complex than parametric responses and currently wrapped in more assumptions than clear rules. But in simple terms, it’s the opposite of relying purely on training memory.
RAG allows the model to retrieve relevant information before answering – querying the web, internal knowledge bases, or document collections in real-time. The process typically involves processing your query, searching for relevant information, ranking the results, and then generating a response that blends the retrieved context with the model’s knowledge.
Instead of answering purely from memory, the model retrieves relevant text and incorporates that fresh context into its response – sometimes citing the source text or linking to where it found the information.
This is where your content optimization efforts matter most.
When an AI tool uses RAG, your content can surface live
As long as it’s clear, well-structured, publicly accessible, and optimized for discoverability.
In other words, RAG is where your content still has a chance to be discovered and cited, even if it wasn’t part of the model’s original training.
When is Parametric knowledge or Rag triggered?
There’s no universal rule. Most AI tools are proprietary, and companies don’t fully disclose their internal decision logic. Still, based on what’s known, here’s how it typically works:
Parametric knowledge is usually the default. The model answers entirely from what it encoded during training (up to its cutoff date).
Parametric knowledge It’s used when:
- The answer can be generated from training knowledge.
- No retrieval component is active (e.g., ChatGPT without browsing).
- The system is designed to be self-contained (like offline models).
Often triggered in conversational queries, such as personal advice, language translations, or general knowledge.
Example:
Q: “Who was the first president of the U.S.?”
→ The model uses parametric knowledge it already has.
RAG It’s used when:
The retrieval-augmented generation kicks in when the system is configured to search an external source (database, search engine, proprietary docs).
It’s used when:
- The query is time-sensitive (e.g., current events, “What’s the Bitcoin price today?”, “X company return policies”).
- The request is transactional (e.g., “buy a yoga mat washing machine friendly”) – because product catalogs change often.
- The request is local (e.g., “vegan restaurants in Paris”).
- The platform is explicitly designed for retrieval (e.g., Bing Chat, Perplexity, ChatGPT with browsing).
Example:
Q: “Who won yesterday’s match at Wimbledon?”
→ The model can’t rely on training data, so it queries the web (RAG).
Hybrid generation: the best of both worlds
Many modern systems blend the two in a single answer. Parametric knowledge provides context, reasoning, and fluency, while retrieval supplies up-to-date or niche facts. This combination often comes with citations for added trust.
Example:
Q: “Is the MacBook Air M2 still a good laptop to buy?.”
→ The model might:
Use parametric knowledge (Explains what the MacBook Air M2 is, and its general specs).
Fetch fresh reviews, price drops, and comparisons against the latest models. via RAG.
Blend both: delivering background + the latest updates, with citations.
Wrapping It Up
Now you know how AI fetches data , and you’re probably left wondering: “So how do I make sure my website shows up when RAG kicks in?”
The short answer: the same principles of good old SEO still apply.
Clear structure, accessible content, and solid optimization are what make your site discoverable, whether by Google or by an AI model pulling fresh results. If your content isn’t optimized, AI won’t have much to find (or cite).
AI-driven search isn’t replacing SEO – it’s raising the bar for it. And the websites that adapt early will be the ones showing up not just in search results, but directly inside the answers people see.
